Attention机制详解
简介
相信做NLP的同学对这个机制不会很陌生,它在Attention is all you need可以说是大放异彩,在machine translation任务中,帮助深度模型在性能上有了很大的提升,输出了当时最好的state-of-art model。当然该模型除了attention机制外,还用了很多有用的trick,以帮助提升模型性能。但是不能否认的时,这个模型的核心就是attention,attention是一种能让模型对重要信息重点关注并充分学习吸收的技术,它不算是一个完整的模型,应当是一种技术,能够作用于任何序列模型中。
Seq2Seq
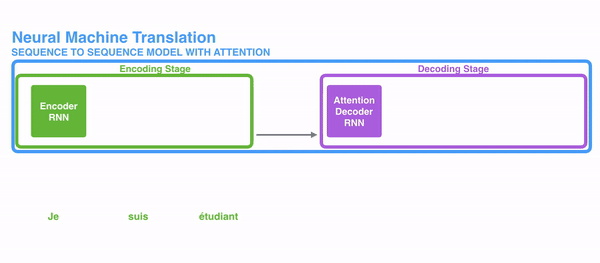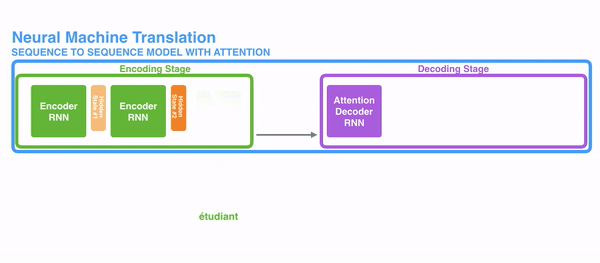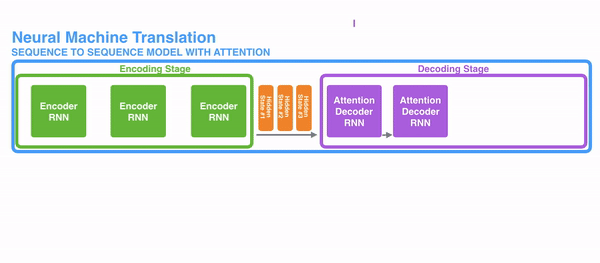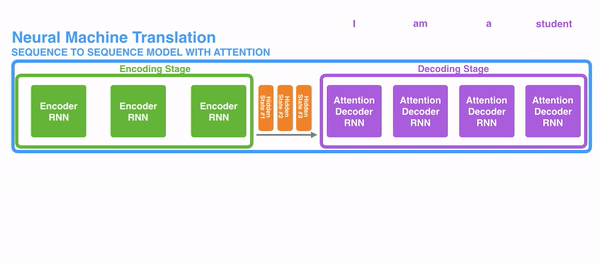
在开始讲解Attention之前,我们先简单回顾一下Seq2Seq模型,传统的机器翻译基本都是基于Seq2Seq模型来做的,该模型分为encoder层与decoder层,并均为RNN或RNN的变体构成,如下图所示
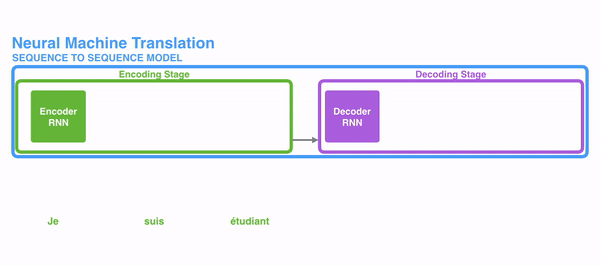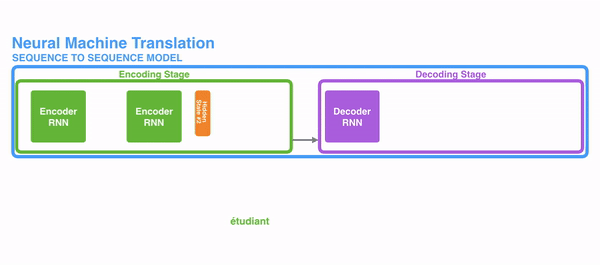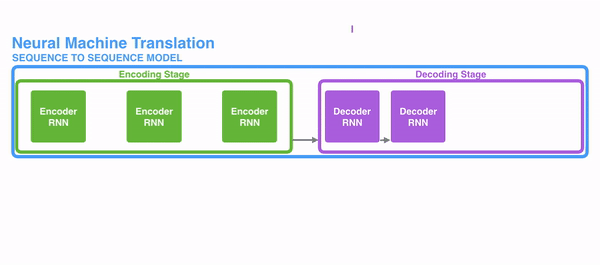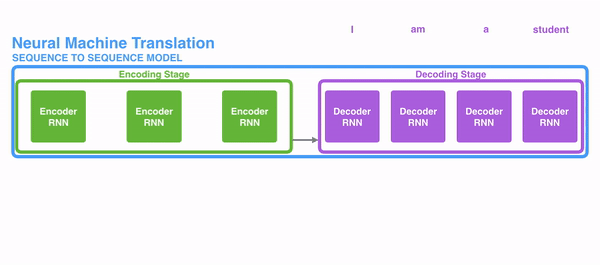
在encode阶段,第一个节点输入一个词,之后的节点输入的是下一个词与前一个节点的hidden state,最终encoder会输出一个context,这个context又作为decoder的输入,每经过一个decoder的节点就输出一个翻译后的词,并把decoder的hidden state作为下一层的输入。改模型对于短文本的翻译来说效果很好,但是其也存在一定的缺点,如果文本稍长一些,就很容易丢失文本的一些信息,为了解决这个问题,Attention应运而生。
Attention
Attention,正如其名,注意力,该模型在decode阶段,会选择最适合当前节点的context作为输入。Attention与传统的Seq2Seq模型主要有以下两点不同。
- encoder提供了更多的数据给到decoder,encoder会把所有的节点的hidden state提供给decoder,而不仅仅只是encoder最后一个节点的hidden state
- decoder并不是直接把所有encoder提供的hidden state作为输入,而是采取一种选择机制,把最符合当前位置的hidden state选出来,具体的步骤如下
- 确定哪一个hidden state与当前节点关系最为密切
- 计算每一个hidden state的分数值(具体怎么计算我们下文讲解)
- 对每个分数值做一个softmax的计算,这能让相关性高的hidden state的分数值更大,相关性低的hidden state的分数值更低
这里我们以一个具体的例子来看下其中的详细计算步骤:
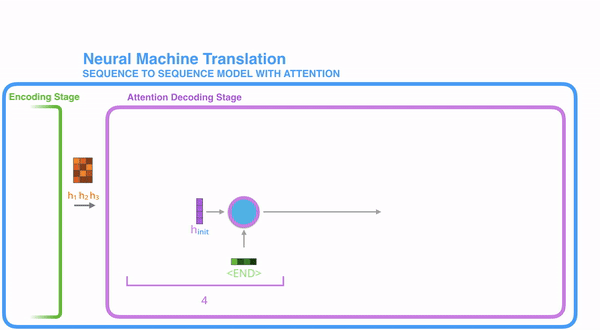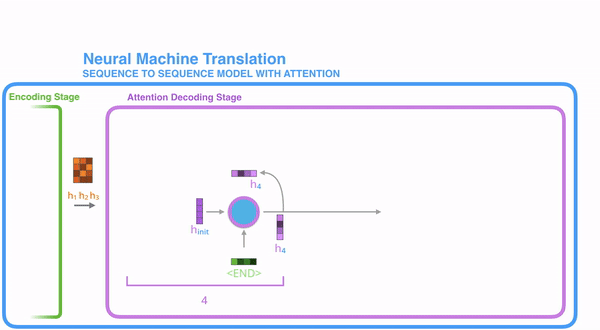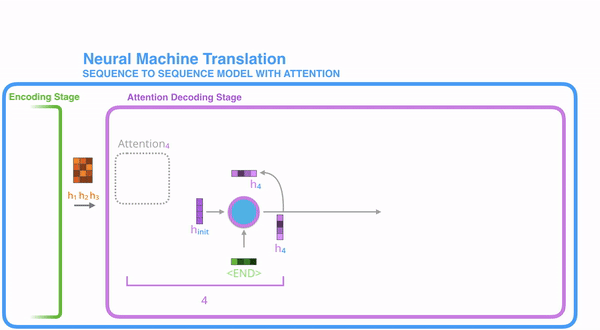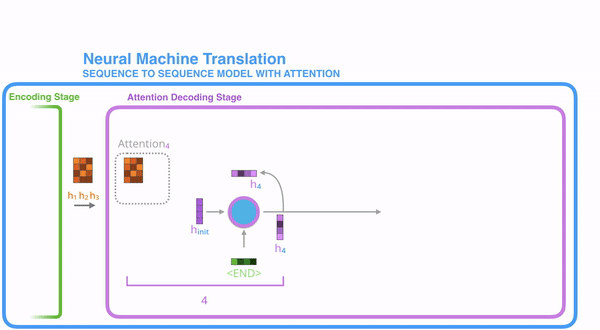
把每一个encoder节点的hidden states的值与decoder当前节点的上一个节点的hidden state相乘,如下图,h1、h2、h3分别与当前节点的上一节点的hidden state进行相乘(如果是第一个decoder节点,需要随机初始化一个hidden state),最后会获得三个值,这三个值就是上文提到的hidden state的分数,注意,这个数值对于每一个encoder的节点来说是不一样的,把该分数值进行softmax计算,计算之后的值就是每一个encoder节点的hidden states对于当前节点的权重,把权重与原hidden states相乘并相加,得到的结果即是当前节点的hidden state。可以发现,其实Atttention的关键就是计算这个分值。

明白每一个节点是怎么获取hidden state之后,接下来就是decoder层的工作原理了,其具体过程如下:
第一个decoder的节点初始化一个向量,并计算当前节点的hidden state,把
Attention模型并不只是盲目地将输出的第一个单词与输入的第一个词对齐。实际上,它在训练阶段学习了如何在该语言对中对齐单词(在我们的示例中是法语和英语)。



