BiMPM
简介
本文是对论文BiMPM:BilateralMulti-PerspectiveMatchingforNaturalLanguageSentences的解读。该模型主要用于做文本匹配,即计算文本相似度。
文本匹配是NLP领域较为常见的技术,但是大部分的匹配方法都是从单一的角度去做匹配,例如ANCNN把两个句子通过同样权重的网络结构,把得到的向量进行相似度计算。BiMPM这个模型最大的创新点在于采用了双向多角度匹配,不单单只考虑一个维度,采用了matching-aggregation的结构,把两个句子之间的单元做相似度计算,最后经过全连接层与softamx层得到最终的结果,不可这也成了其缺点,慢。
结构
BiMPM的主要结构如图
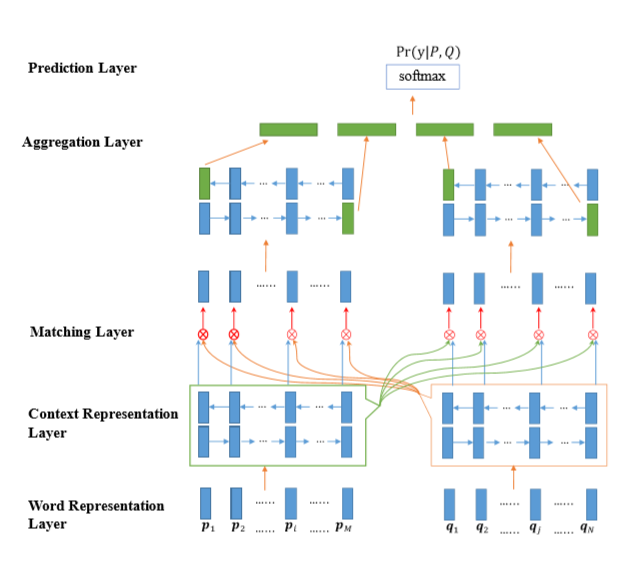
可以看到,该模型一共包含五层,每一层各尽其职,接下来我们把这五层分开来详细说明。
Word Representation Layer
该层的目标是把输入的序列P与Q转变为d维的向量表示,该向量由两个部分组成,分别是普通的词向量和由字符构成的向量,字符向量的值是把所有的字符输入到LSTM中得到的结果。本层实际上即是文本的向量化表示embedding。
ContextRepresentationLayer
本层主要是用于提取P与Q的上下文信息,把上一层拿到的embedding输入到BiLSTM中,分别得到两个方向不同时刻的context embedding
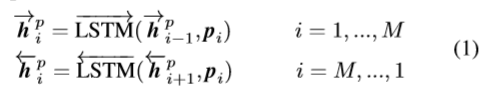
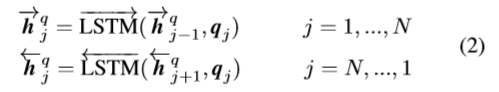
Matching Layer
Matching Layer是该模型的核心层,多维度匹配,该层的目标是把每一个序列不同时刻的context与另一个序列的所有时刻的context做一个比较,并且考虑了两个方向,这里设计了一种 multi-perspective 的匹配方法,用于获取两个句子细粒度的联系信息,其中具体的比较细节我们会在下文讲解。
Aggregation Layer
本层的目的就是把上一层的结果聚集在一起,合并成一个固定长度的向量,采用的依旧是BiLSTM模型。
Prediction Layer
最后就是预测层了,这个阶段包括两个全连接层与一个softmax层或sigmoid层,具体看业务场景。
多维度匹配
接下来我们会把Matching Layer中提到的匹配机制进行一个详细说明,首先作者定义了一个多角度匹配的相似度函数
其中$v_1$与$v_2$表示的是两个$d$维度的向量,$W \in R^{l×d}$是权重,其维度为$(l,d)$其中$l$表示的是匹配的角度数量,结果$m$是一个$l$维度的向量,$m=[m_1,…,m_k,…,m_l]$,每一个$m_k$表示的是第$k$个角度的匹配结果,其值的相似度计算方法如下
$f_m$实际上又有四种策略来求相似度,分别看下
Full-Matching
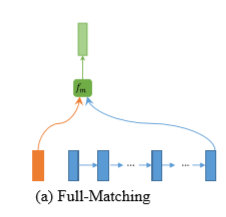
该方法会把每一个时刻的context与另一个序列的尾的context做一个相似度计算
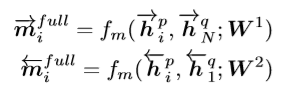
Maxpooling-Matching
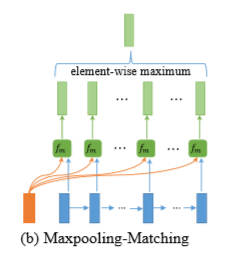
该方法会把P序列所有时刻的context与Q序列所有时刻的context做一个相似度计算,最后只保留相似度最大的那个值,
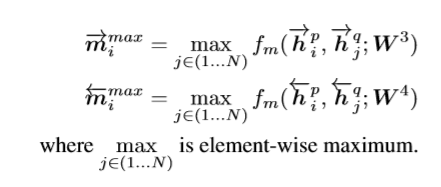
### Attentive-Matching
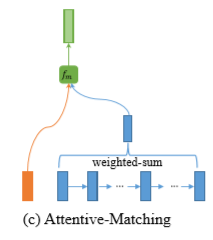
该方法首先会计算P序列每一个时刻的context与Q序列每一个时刻的context的相似度
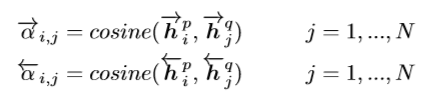
然后把得到的相似度作为对应时刻的权重与另一个序列做加权平均,针对整个序列计算出attentive vector
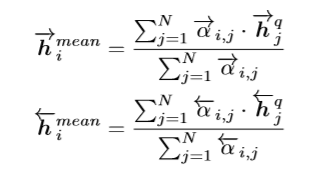
最后把每一个时刻的context与attentive vector做一个相似度计算
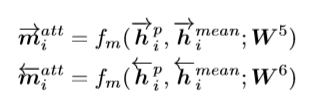
### Max-Attentive-Matching
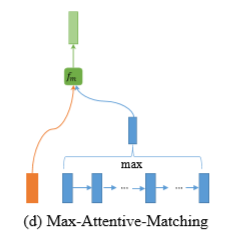
该方法其实和Attentive-Matching方法类似,不过是把最后生成attentive vector的方法改为了求最大值而不是加权平均
序列的每一个时间步长都通过这四种策略得到相似度的值,由于是双向的,最终将生成的8个向量串联起来作为的每个时间步长的匹配向量。
总结
BiMPM有两个优化的点,第一个是不单单只考虑词向量,同时兼顾了字向量,其次其更加注重句子之间交互信息,从不同层次不同粒度来匹配待比较的句子,加大了比较范围,效果必然是会有一定的提升,但是也因此引入了更多的参数,加大了训练难度。



