BN算法讲解
背景
自从2012年以来,CNN网络模型取得了非常大的进步,而这些进步的推动条件往往就是模型深度的增加。从AlexNet的几层,到VGG和GoogleNet的十几层,甚至到ResNet的上百层,网络模型不断加深,取得的效果也越来越好,然而网络越深往往就越难以训练。我们知道,CNN网络在训练的过程中,前一层的参数变化影响着后面层的变化,而且这种影响会随着网络深度的增加而不断放大。
在CNN训练时,绝大多数都采用mini-batch使用随机梯度下降算法进行训练,那么随着输入数据的不断变化,以及网络中参数不断调整,网络的各层输入数据的分布则会不断变化,那么各层在训练的过程中就需要不断的改变以适应这种新的数据分布,从而造成网络训练困难,难以拟合的问题。 举个例子,比如10个batch,前8个要求z方向+0.1,后两个要求z方向-0.4,最终有效梯度为0.8-0.4*2=0,这种竞争消耗着效率。
对于深层模型,越底层,越到训练后期,这种batch梯度之间的方向竞争会变得厉害(这是统计上的,某个时刻不一定成立),类似饱和。深层模型都用不着坐等梯度衰减,光是batch方向感就乱了训练效率。
BN算法解决的就是这样的问题,他通过对每一层的输入进行归一化,保证每层的输入数据分布是稳定的,从而达到加速训练的目的。
Batch Normalization的优势
1、可以选择比较大的初始学习率,让你的训练速度飙涨。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性
2、具有一定的regularization 作用, 可以减少 Dropout 的使用,dropout的作用是防止overfitting, 实验发现, BN 可以reduce overfitting
3、降低L2权重衰减系数
4、不再需要使用使用局部响应归一化(LRN)层了(LRN实际效果并不理想)
为什么要归一化
开始讲解算法前,先来思考一个问题:我们知道在神经网络训练开始前,都要对输入数据做一个归一化处理,那么为什么需要归一化呢?
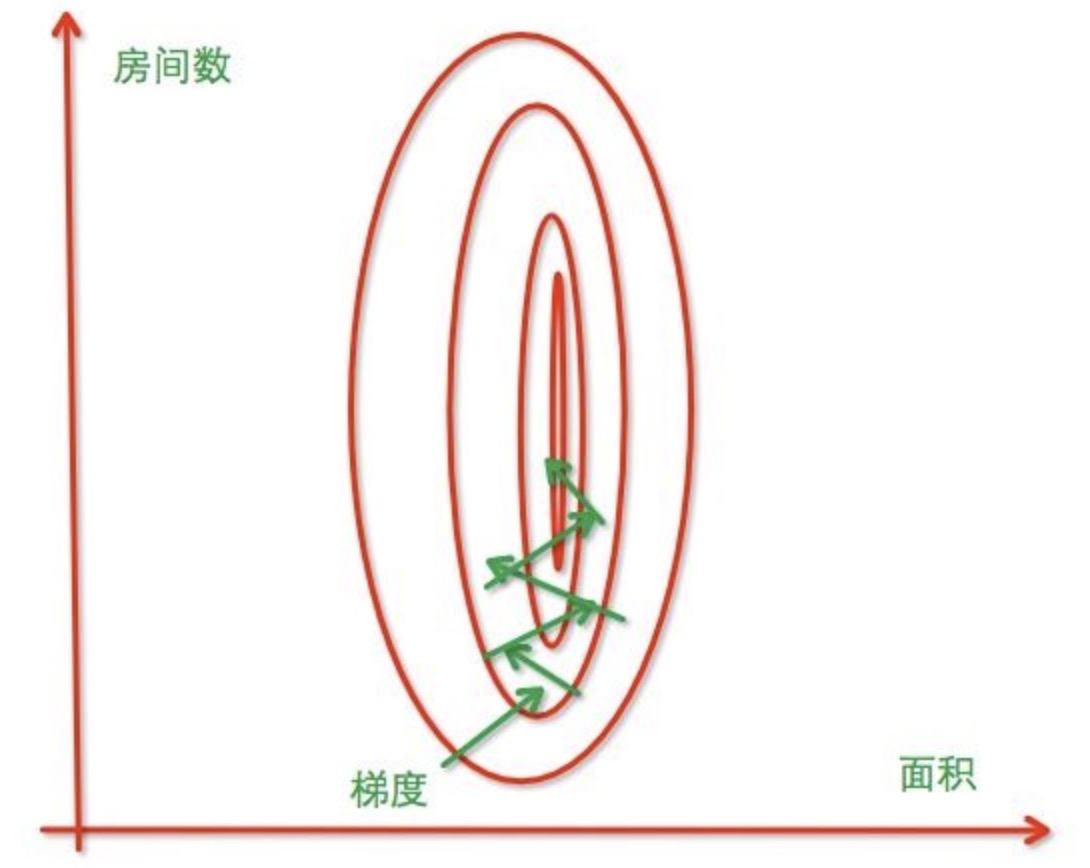
我们先看个例子,假设为预测房价,自变量为面积与房间数,因变量为房价。 那么可以得到的公式为:
y = w1x1 + w2x2
其中,x1为面积,w1为面积的系数,x2为房间数,w2为房间数的系数
我们假定单位面积的房价是10w,每个房间的额外费用是500,最终
y = 100000x1 + 500x2
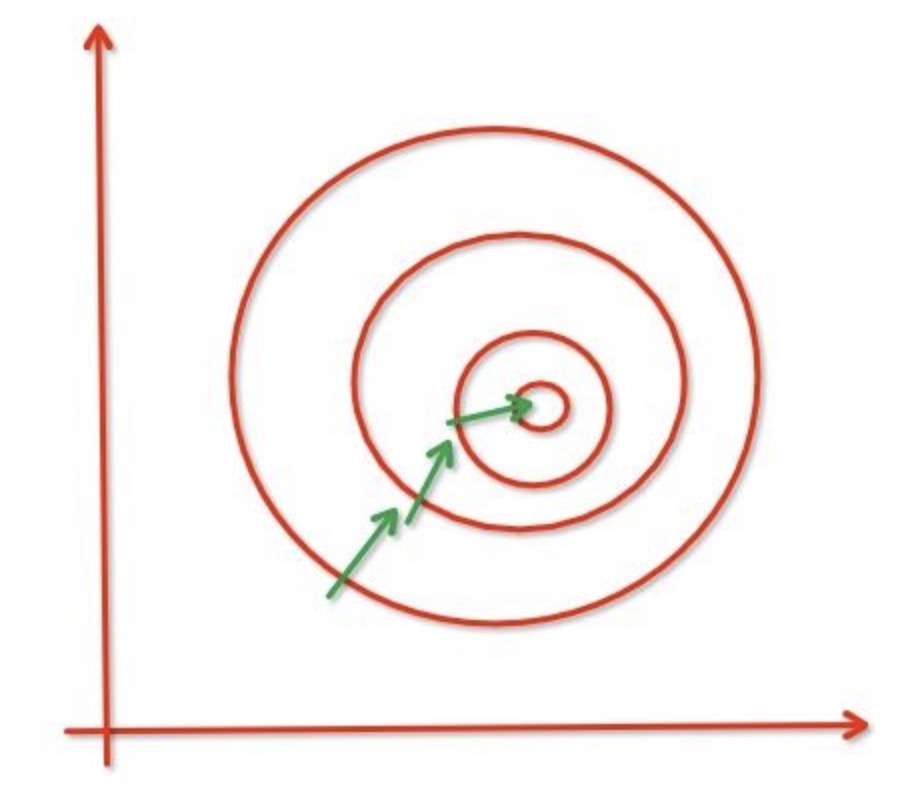
x1的轻微变化就会对结果产生巨大的影响,其次,在BP过程中,x2的系数相对较小,收敛过程就会变慢。如果我们把系数都变为同一个范围,那么x1与x2对结果的影响就是一样的,收敛速度就会变快。
未归一化:
归一化:
Batch Normalization算法讲解
在神经网络中,我们会在输入层对数据进行归一化,Batch Normalization则是在每一层输出的时候插入了一个归一化层,将输入数据的归一化为均值为0,方差为1的分布
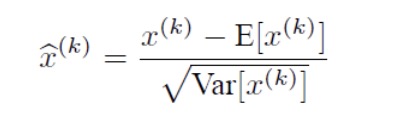
其中,x(k)表示输入数据的第k维,E[x(k)]表示该维的平均值,√Var[x(k)]表示标准差。归一化之后把数据送入下一层。
但是这样是会影响到本层网络所学习到的特征的。打个比方,比如我网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧,你强制把它给我归一化处理、标准差也限制在了1,把数据变换成分布于s函数的中间部分,这样就相当于我这一层网络所学习到的特征分布被你搞坏了,这可怎么办?BN还有另一招:变换重构,引入了可学习参数γ、β,这就是算法关键之处:
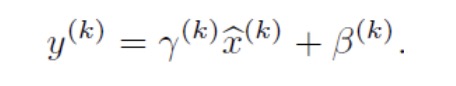
每一个神经元都对应着xy,当
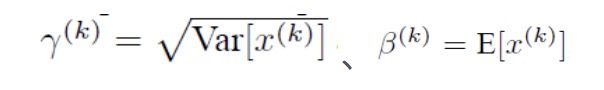
时是可以恢复出原始的某一层所学到的特征的。因此我们引入了这个可学习重构参数γ、β,让我们的网络可以学习恢复出原始网络所要学习的特征分布。这里的γ、β我们可以理解为w和b,也是需要训练出来的。最后我们看下总的推导公式。

求x时,公式中的ε是一个及其小的数,这里引入是为了防止分母为0。m指的是mini-batch size。
需要注意的是,上述的计算方法用于在训练过程中。在测试时,所使用的均值和标准差是整个训练集的均值和标准差. 由于训练集的数量较大,均值和标准差的计算量是很大的,所以一般会使用移动平均法来计算。以下是整一个BN算法。

在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。



