LSTM网络讲解
LSTM 网络
长短期记忆网络(Long Short Term)通常也被简称为LSTM,是一种特殊类型的RNN,能够学习长期的依赖关系。LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
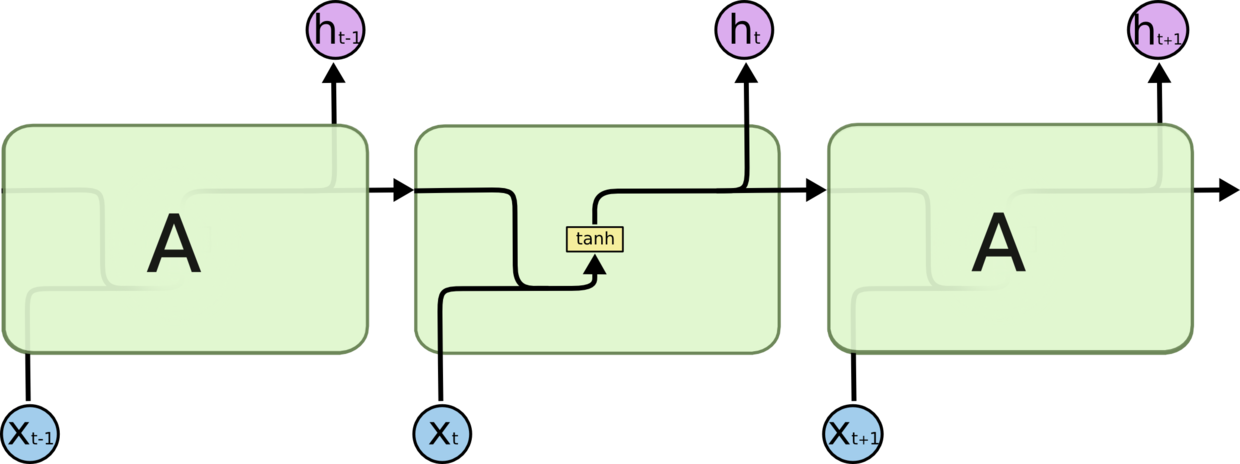
LSTM 同样是这样的结构,不同于单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
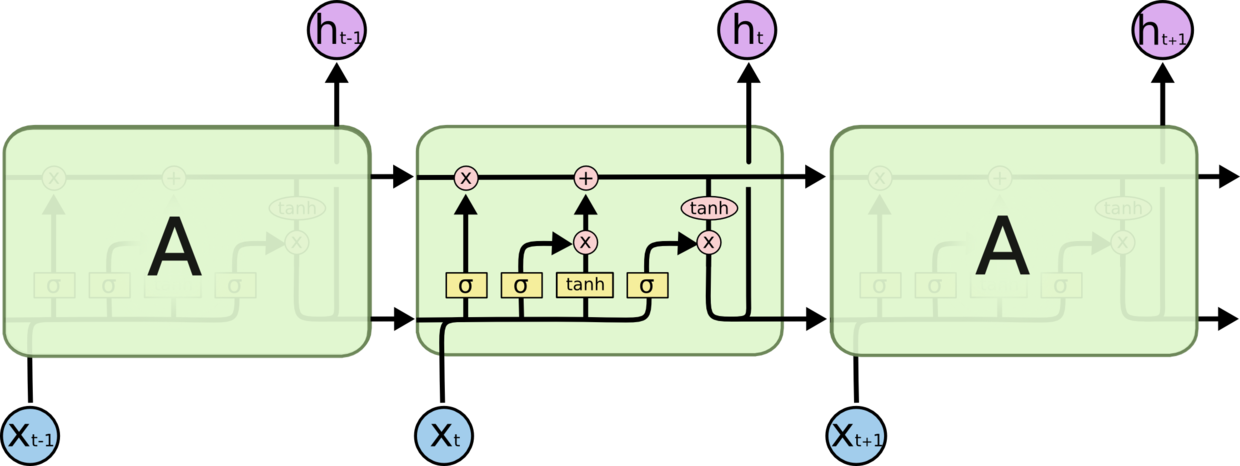
其次,LSTM额外添加了一个细胞状态,这里我们用$C$来表示,也就是下图这条向右的线
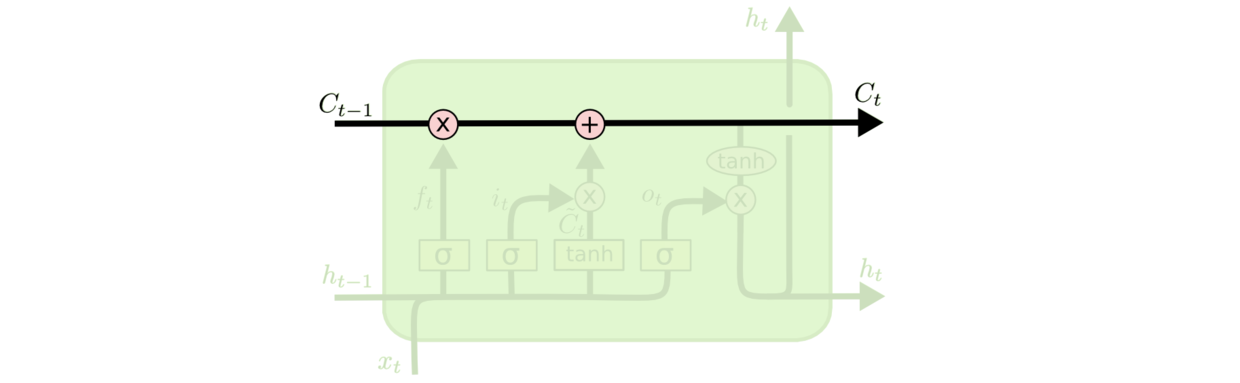
细胞状态会沿着整条链条传送,而只有少数地方有一些线性交互。如果遗忘门没有状态的移除且输入门(下文会详细讲解)没有新状态的增加,那么最终$C_T = C_0$,从而保证了细胞状态的长期依赖。
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到状态的能力。理解“门”就是LSTM网络的关键,而LSTM的“门”分为了三种,忘记门,输入门,输出门,接下来我们就详细介绍下这三个门。
遗忘门
首先,LSTM 的第一步需要决定我们要抛弃哪些细胞的状态信息。这个决定是依靠遗忘门来实现的,具体的结构如图,输入是$h_{(t-1)}$与$x{(t)}$,经过sigmoid函数后,输出了一个0-1之间的值,0代表完全移除,1代表完全保留。
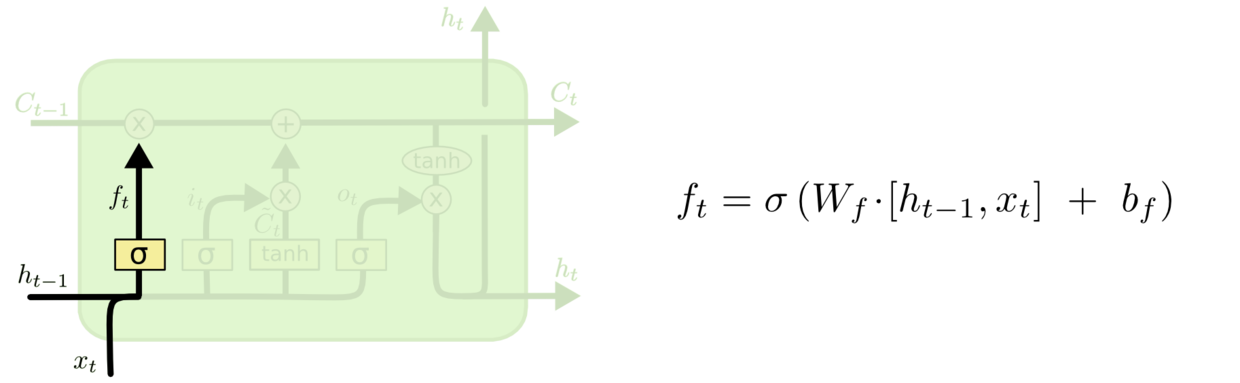
这里我们拿基于已经看到的预测下一个词的模型来举例,在这个问题中,当前状态可能包含当前主语的类别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。例如:他今天有事,所以我…当处理到“我“的时候选择性的忘记前面的“他“,或者说减小这个词对后面词的作用。
输入门
经过遗忘门之后,我们需要决定什么样的细胞状态应该被添加进来。这个过程主要分两步。首先是$sigmoid$,同样输出一个0-1的值,从而决定我们需要更新哪些值。随后,$tanh$生成了一个新的候选向量$\tilde{C}$,将这两个值相乘最后得到需要输入的值。
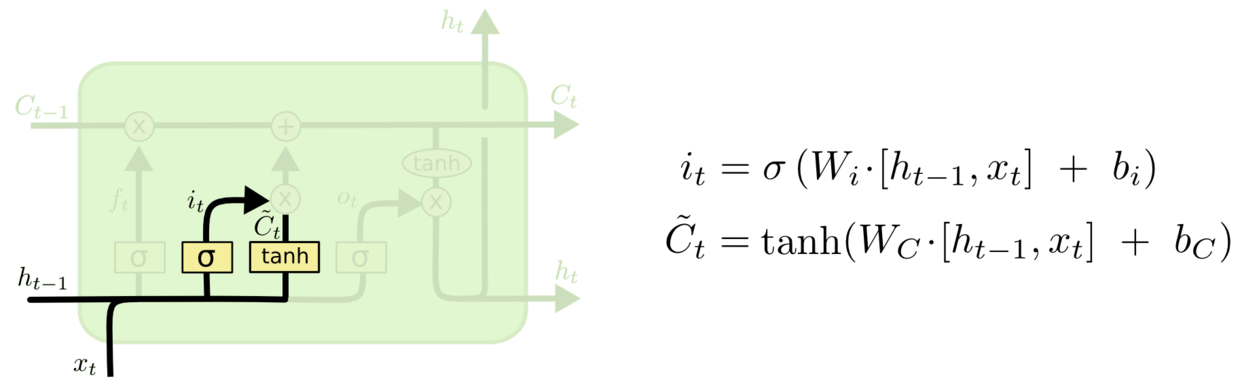
我们继续用前面的模型举例子,我们希望增加新的主语的类别到细胞状态中,来替代旧的需要忘记的主语。 例如:他今天有事,所以我。。。。当处理到“我“这个词的时候,就会把主语我更新到细胞中去。
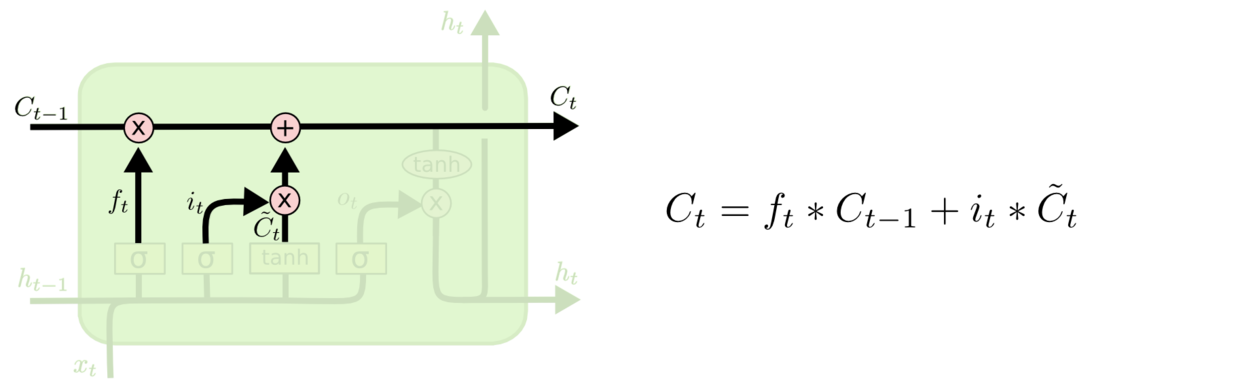
接下来,我们就可以更新细胞状态了。将旧的细胞状态$C_{t-1}$与$ft$相乘,忘记此前我们想要忘记的内容,然后加上输出门的值$i_t*\tilde{C}$。得到的结果便是新的细胞状态。
输出门
最后,我们需要输出细胞状态,即输出门。首先我们会运行一个$sigmoid$层决定细胞状态输出哪一部分。随后,我们把细胞状态通过$tanh$函数,将输出值保持在-1到1之间。之后,我们再乘以$sigmoid$的输出值,就可以得到结果了,最后将加过加入到隐藏状态中。
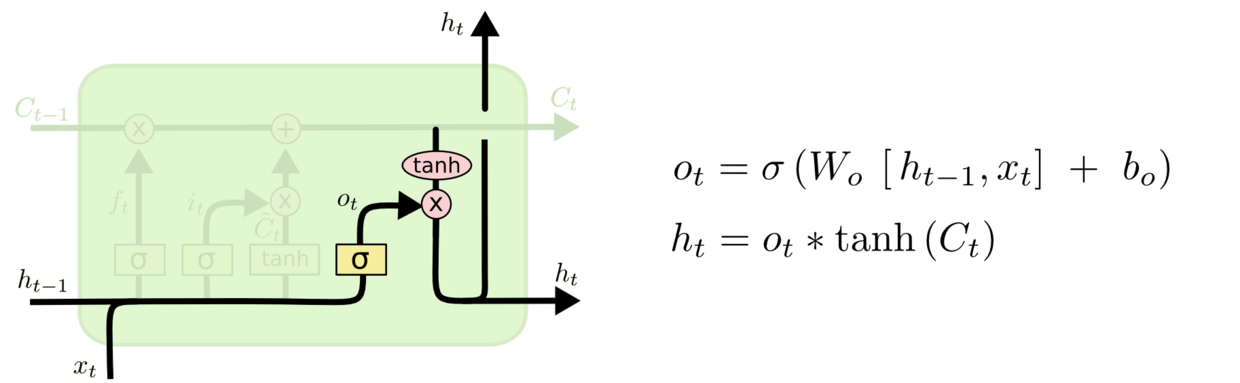
对于语言模型的例子,当它只看到一个主语时,就可能会输出与动词相关的信息。比如它会输出主语是单数还是复数。这样的话,如果后面真的出现了动词,我们就可以确定它的形式了。例如,The cat,which already ate…,was full,当处理到was的时候,由于前面获取的主语是cat,因此输出结果was,如果前面主语是cats,那么输出结果就是were。
LSTM变体
我们到目前为止都还在介绍正常的 LSTM。但是不是所有的 LSTM 都长成一个样子的。实际上,几乎所有包含 LSTM 的论文都采用了微小的变体。这里,我们简单介绍下目前比较流行的GRU。
GRU是由 Cho, et al. (2014) 提出。它将忘记门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,计算的复杂度更低,但是没有LSTM灵活。

结论
LSTM 对于 RNN 来说是一个大的进步。在有了 LSTMs 后,越来越多的任务都可用 RNN 来解决了。那么自然地,我们会想:是否还会有下一个 LSTM 式的飞跃呢?学界普遍的一个答案是,会的!下一步就是 attention 了。Attention 是什么?也就是说,从 RNN 的每一步中提取信息,并形成一个更大的信息集合。比如使用 RNN 产生能描述图片的标题时,它可能只选择图片的一部分进行关注。实际上,Xu, et al. (2015) 就是这样做的——这可能会成为你探索 attention 算法的一个切入口。目前采用 attention 的研究也已经取得了不少进展,可能已经走到了飞跃的十字路口吧。



