NLP模型浅析
前言
DP算法在图像识别领域取得了惊人的效果,近些年,也不断有人挖掘除了语言这种高层次抽象中的本质,从而让DP在NLP领域不断取得新的突破,其中最关键的核心技术就是Word2Vec,也称Word Embeddings,中文有很多叫法,比较普遍的是”词向量”或“词嵌入”。本文也将会从这个点开始讲起。
词向量
要把自然语言处理问题转换为机器可以理解的内容,第一步就是要想办法把自然语言转换为数字,到目前为止,最直观的表示方法就是One-hot, 首先建立一个词汇表,对于每个具体的词汇表中的词,将对应的位置置为1,其他位置设为0。例如一个用来表示10000个词汇的词汇表,
苹果(5304) 苹果这个词向量是在第5304的位置为1其他位置为0,我们用$O_{5304}$表示苹果
西瓜(9230) 西瓜这个词向量是在第9230的位置为1其他位置为0,我们用$O_{9230}$表示西瓜
用这种方式来表示词汇会非常简洁,每个单词分配一个对应的ID即可,但是也有其缺点,首先该形式的词向量是很冗长的,其次这种方法会让每个词汇孤立起来,例如苹果和西瓜,本质上都是水果,但是机器没法找出其中的关系。为了解决这个问题,我们引入了一种特征化的表示方法Dristributed representation。看个例子。
我们针对四个词,人为的给他们添加了特征值,当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释,而是需要使用神经网络来计算出来。我们把它称之为嵌入矩阵$E$
| 男人 | 女人 | 苹果 | 西瓜 | |
|---|---|---|---|---|
| 性别 | 1 | -1 | 0 | 0.001 |
| 水果 | 0.001 | 0.0002 | 0.98 | 0.99 |
| 食物 | 0.002 | 0 | 1 | 0.97 |
| … | … | … | … | … |
假设我们对每个词汇进行了300次的特征标注,那么每个词汇的的词向量长度就是300,例如这里的苹果我们用$e_{5304}$表示,值为
西瓜用$e_{9230}$表示,值为
这里我们提供一个求词向量的公式
如果我们把200维的向量降为2维的,并在图中标注出来,就会发现,关系越接近的位置就越接近。
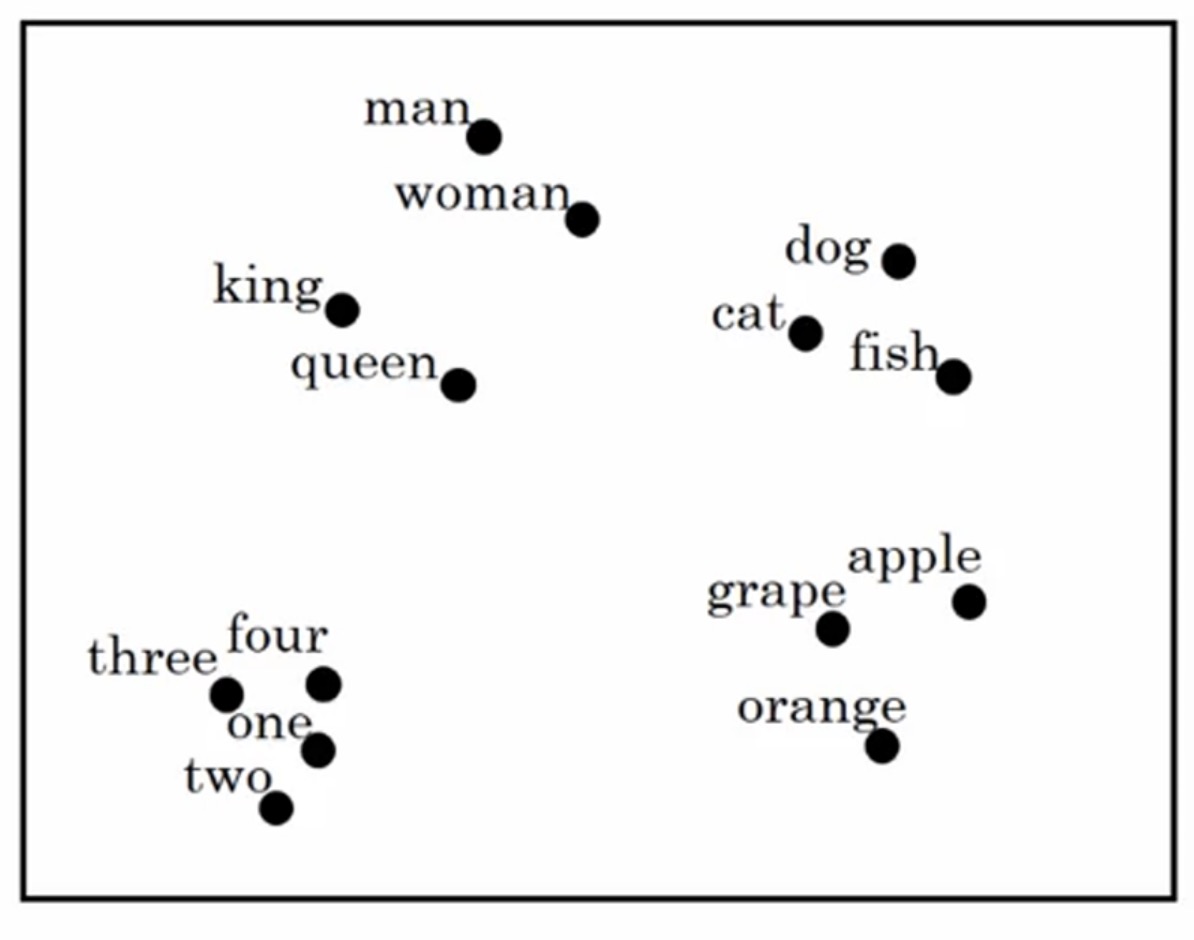
为了理解词向量的特征,我们再看一个例子,我们有一个这样的问题,男人->女人,那么国王->?,我们都可以猜测到国王->皇后。那么,机器能否自动推导出这种关系呢,下面就是实现的方法。
| 男人 | 女人 | 国王 | 皇后 | |
|---|---|---|---|---|
| 性别 | 1 | -1 | 0.97 | -0.96 |
| 年纪 | 0.001 | 0.0002 | 0.93 | 0.94 |
| 食物 | 0.002 | 0 | 0 | 0.001 |
我们这里假设每个词只有3个特征值,那么
所以有
语言模型
目前一些主流的语言模型算法简介且功能强大,本文会先从最基础的模型讲起,这些基础模型可能会稍复杂些,但是对之后的模型理解会有很多帮助。
我们还是以一个例子来讲解,我们有一个10000个词的嵌入矩阵,这里我们需要预测某个词 I want a glass of orange __
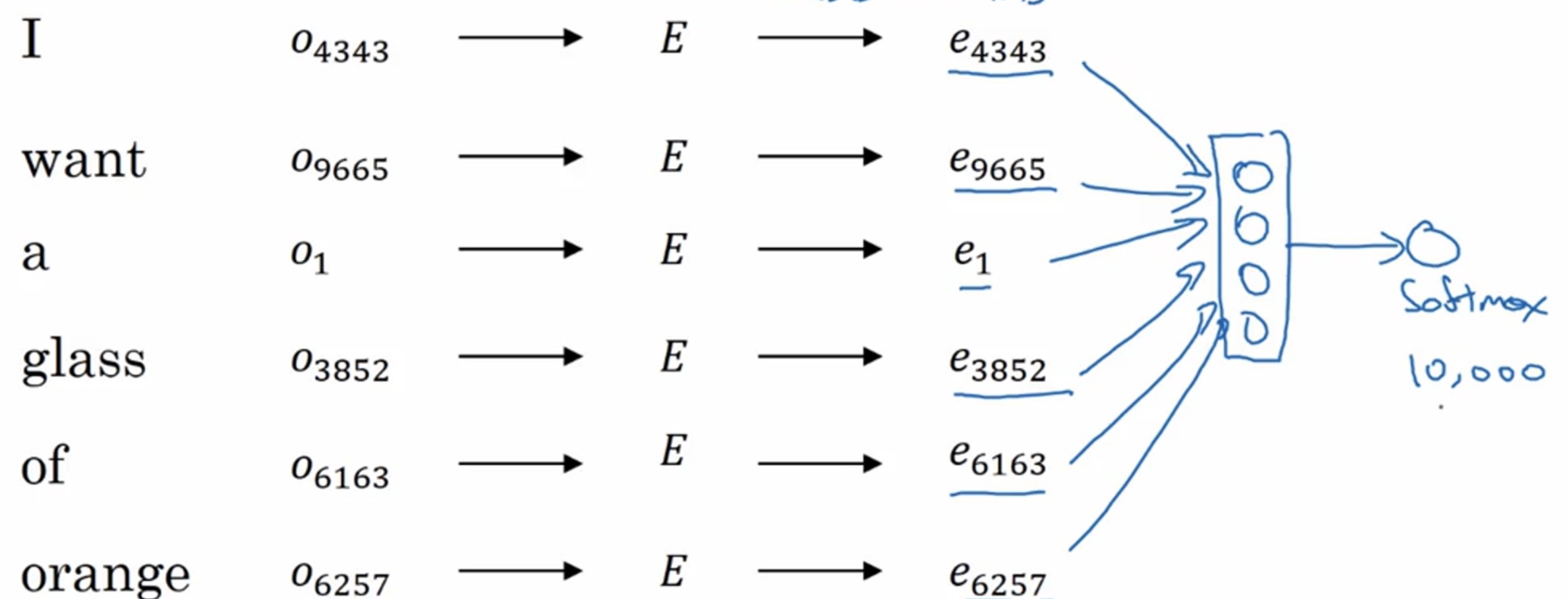
首先,我们从嵌入矩阵中取出每个词对应的词向量,之后把它们全部放进神经网络中,经过神经网络后,在通过一个softmax层,最后这个softmax分类器会在10000个词中预测出句子结尾的是juice。
在上一个例子中,我们是把整句话都做为上下文都输入到了神经网络中,其实在语言模型中,我们可以不用输入整句,这里整理了4种输入到神经网络的上下文的种类
- 目标的上n个词
- 目标词左右的n个词
- 目标的上一个词
- 目标附近的一个词
Skip-Gram
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型。从直观上理解,CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量,例如输入I want a glass of orange __ 输出结果是juice。Skip-Gram输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。我们这里继续使用I want a glass of orange juice 来举例,假设输入是orange,我们取上下文的大小是2,因为orange后面只有一个词,所以输出结果就是softmax概率排前3的3个词。
Skip-Gram分为两个步骤,第一步是建立模型,求嵌入矩阵,第二步是通过模型获取词向量
Skip-Gram模型一共分为3层,输入层,隐藏层,输出层。其中输入是一个ont-hot向量,经过隐藏层后会得到词向量,注意,这里的隐藏层的参数其实就是上文提到的嵌入矩阵,这个矩阵的参数是反向传播求出来的而不是人为规定的。最后再经过softmax层获得对应的概率。
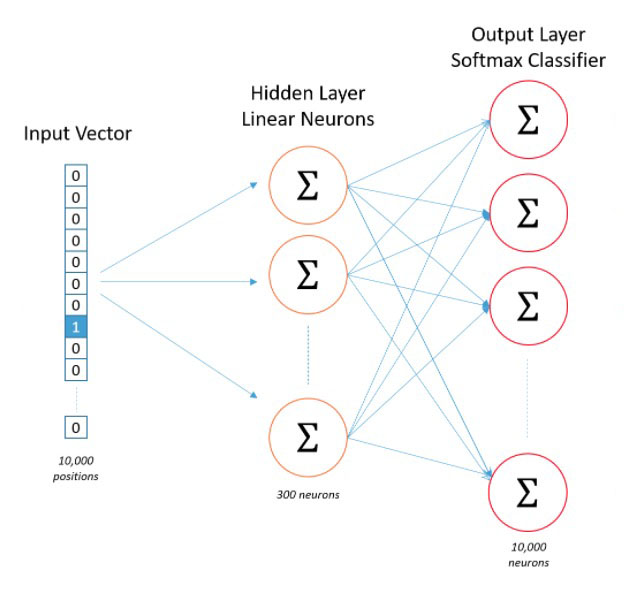
我们继续以上面的例子来讲解,假设我们词汇表一共有10000个词,词向量的维度是300,那么输入值就是一个10000维的Ont-hot向量,经过隐藏层即一个10000×300的嵌入矩阵,得到一个1×300的词向量,最后经过300×10000的softmax输出层,即可获取概率排前3的3个词。
你可能注意到Skip-Gram实在是太巨大了。在我给的这个例子,每个词向量由300个元素组成,并且一个单词表中包含了10000个单词。回想神经网络中有两个权重矩阵——一个在隐藏层,一个在输出层。这两层都具有300 x 10000 = 3,000,000个权重!使用梯度下降法在这种巨大的神经网络下面进行训练是很慢的。并且可能更糟糕的是,你需要大量的训练数据来调整这些权重来避免过拟合。上百万的权重乘以上十亿的训练样本,意味着这个模型将会是一个超级大怪兽!
针对这个问题,Skip-Gram的作者提出了3个解决方案
- 对于常见的单词对或者短语,在模型中将他们视为单个的单词。
- 对常见单词进行二次采样来减少他们在训练样本中的数量。
- 使用所谓的“负采样”(negative sampling)来改进优化对象,这将造成每一个训练的样本只会更对模型权重的很小一个比例的更新。
我们这里主要讲解下负采样。
负采样通过使每一个训练样本仅仅改变一小部分的权重而不是所有权重,从而解决这个问题。下面介绍它是如何进行工作的。
首先,我们将softmax输出层改变成10000个sigmod二元分类层,每一个输出的值为0或1,0代表不是对应的单词,1代表是对应的单词,但有新的数据进入到输出层的时候,我们就不需要修改300×10000的参数,只需要修改对应的sigmod函数的参数此处仅为300个。
那么,什么是负样本呢,例如上面的例子,orange对应的单词可以是juice、glass,而paper、king这样的单词没有出现,就是所谓的负样本,我们一般选取5-20个这样的负样本,一般如果数据集越大那么负样本所需数量就越少,这里我们取5个负样本,一个正样本juice,最终我们的输出层只需要更新1800个参数,这些总共仅仅是输出层中3百万个权重中的0.06%。
注意,在隐藏层中,只更新了输入单词对应的权重不论你是否使用了负采样。
从本质上来说,选择一个单词来作为负样本的概率取决于它出现频率,对于更经常出现的单词,我们将更倾向于选择它为负样本。


