DIIN讲解
本文是我的匹配模型合集的其中一期,如果你想了解更多的匹配模型,欢迎参阅我的另一篇博文匹配模型合集
所有的模型均采用tensorflow进行了实现,欢迎start,代码地址
简介
DIIN模型和其他匹配模型的结构都很接近,也是采用CNN与LSTM来做特征提取,但是在其输入层,作者提出了很多想法,同时采用了词向量、字向量,并且添加了一些额外的特征例如词性等,其本意在于能额外输入一些句法特征,CNN部分也采用了DenseNet的结构,接下来就为大家详细介绍该模型。
结构
DIIN的结构主要分为五层,分别是Embedding Layer、Encoding Layer、Interaction Layer、Feature Extraction Layer、Output Layer,主要结构如下图所示
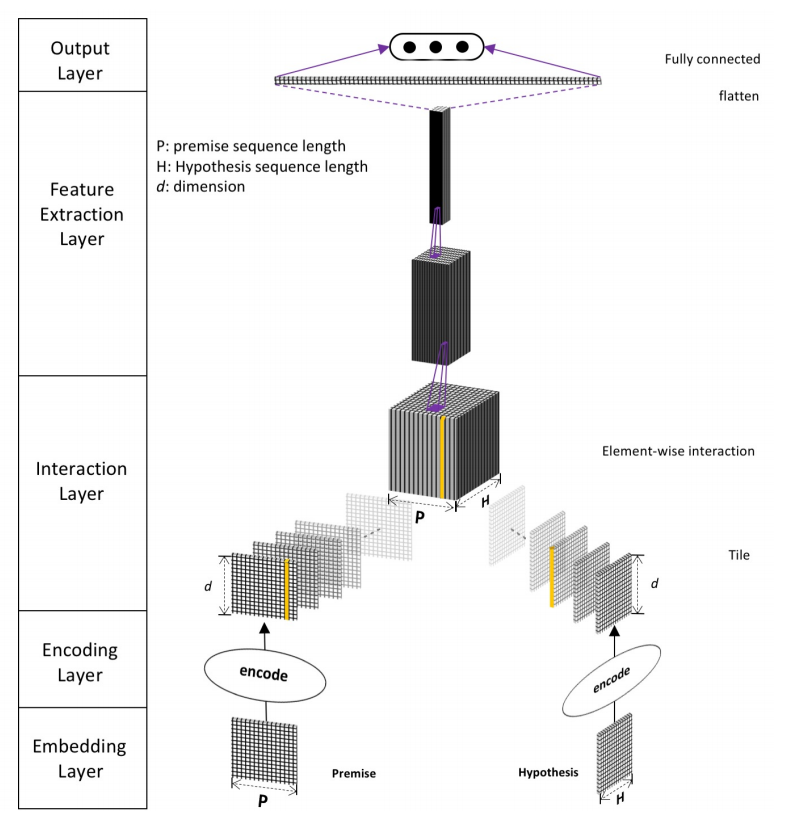
Embedding Layer
Embedding Layer会把每一个词或者说段落转变为向量表示,和其他模型不同的点在于其不仅仅只采用了字、词向量,还添加句法特征。其中词向量是用预训练好的模型得到的,并且在训练的过程中继续更新。而对于字向量则是先采用了1维卷积加最大池化层的方式来提取特征,其中卷积核对于P与H来说是共享的,字向量可以有效降低OOV引起的误差。对于句法特征,包含了one-hot形式的词性特征与exact match特征,exact match主要是针对英文,在去除时态、单复数等情况下两个句子里的词是否一样,在中文中这个特征我们就不考虑了,在我的代码实现中主要以前三个特征为主。
Encoding Layer
Encoding Layer的主要作用是将上一层的特征进行融合并进行encode。论文中作者采用的是self-attention机制,同时考虑到了词序和上下文信息。以P作为例子,首先计算attetion matrix
这里的attention matrix的 计算方法和transformer的还不太一样,作者取了三个维度的值并拼接起来,如下面的公式所示,我的理解是a与b应该是一样的,因为都是针对的P,唯一多了个$a\circ b$其中的$\circ$是对位相乘,如果P的维度是$d$,那么拼接后的向量维度是$3d$
然后加上softmax计算self-attention的值
接下来作为引入了LSTM中门的概念semantic composite fuse gate,其计算公式如下
其中$W$的维度均是$[2d,d]$,$b$的维度是$d$,$\sigma$表示的是sigmoid函数
H的操作和P的操作一样,就不再赘述了,有一点需要注意,论文中人为P和H是有细微差距的,所以attention的权重和gate的权重是没有共享的,不过论文中的任务五是NLI,如果是相似度匹配的任务我觉得此处是可以共享的,必须相似度匹配两个句子本身就是很接近的,此观点仅代表个人想法没有验证过,代码中我们还是以论文为主。
Interaction Layer
Interaction Layer的主要目的是把P与H做一个相似度的计算,提取出其中的相关性,可以采用余弦相似度、欧氏距离等等,这里作者发现对位相乘的想过很好,所以公式中的$\beta(a,b) = a \circ b$
Feature Extraction Layer
Feature Extraction Layer的任务正如其名,做特征提取。这一层论文主要采用的是CNN的结构,作者实验发现ResNet效果会好一些,但是最终还是选择了DenseNet,因为DenseNet能更好的保存参数,并且作者观察到ResNet如果把skip connection移除了模型就没法收敛了(ResNet的关键就在于skip connection不知道作者为什么要说明这一点)BN还会导致收敛变慢(这里应该是指针对当前这个模型来说)所以作者并没有采用ResNet。卷积采用的是relu激活函数,都是1×1的卷积核来对上文提到的相关性tensor进行缩放,并且这里引入了一个超参数$\eta$,例如输入的channel是$k$那么输出的channel就是$k×\eta$,然后把结果送到3层Dense block中,Dense block包含了n个3×3的卷积核,成长率是$g$,transition layer采用了1×1的卷积核来做channel的缩减,然后跟上一个步长为2的最大池化层,transition layer的缩减率用$\theta$表示。这一层的关键就在于DenseNet,对DenseNet不清楚的小伙伴一定要先去了解该网络的结构原理,这也是为啥作者会把该模型取名为Densely Interactive Inference Network
Output Layer
最后就是输出层了,全连接层+softmax层,不再赘述。
小结
DIIN相比于之前介绍的匹配模型,最大的改进点在于输入的特征变多,其次特征提取时采用了DenseNet,但在Interaction层并没有做多维度的匹配,如果结合BiMPM的结构,把该部分从多个不同的粒度进行匹配,效果应该还会进一步的提升,和其论文标题也会更加稳合一些。