DSSM详解
本文是我的匹配模型合集的其中一期,如果你想了解更多的匹配模型,欢迎参阅我的另一篇博文匹配模型合集
所有的模型均采用tensorflow进行了实现,欢迎start,代码地址
简介
DSSM是2013年提出来的模型论文地址,主要应用场景为query与doc的匹配,在这之前,用的更多的还是一些传统的机器学习算法,例如LSA,BM25等。DSSM也算是深度学习在文本匹配领域中的一个先驱者,接下来我们会先从其结构开始讲起,并简单介绍下其变体。
结构
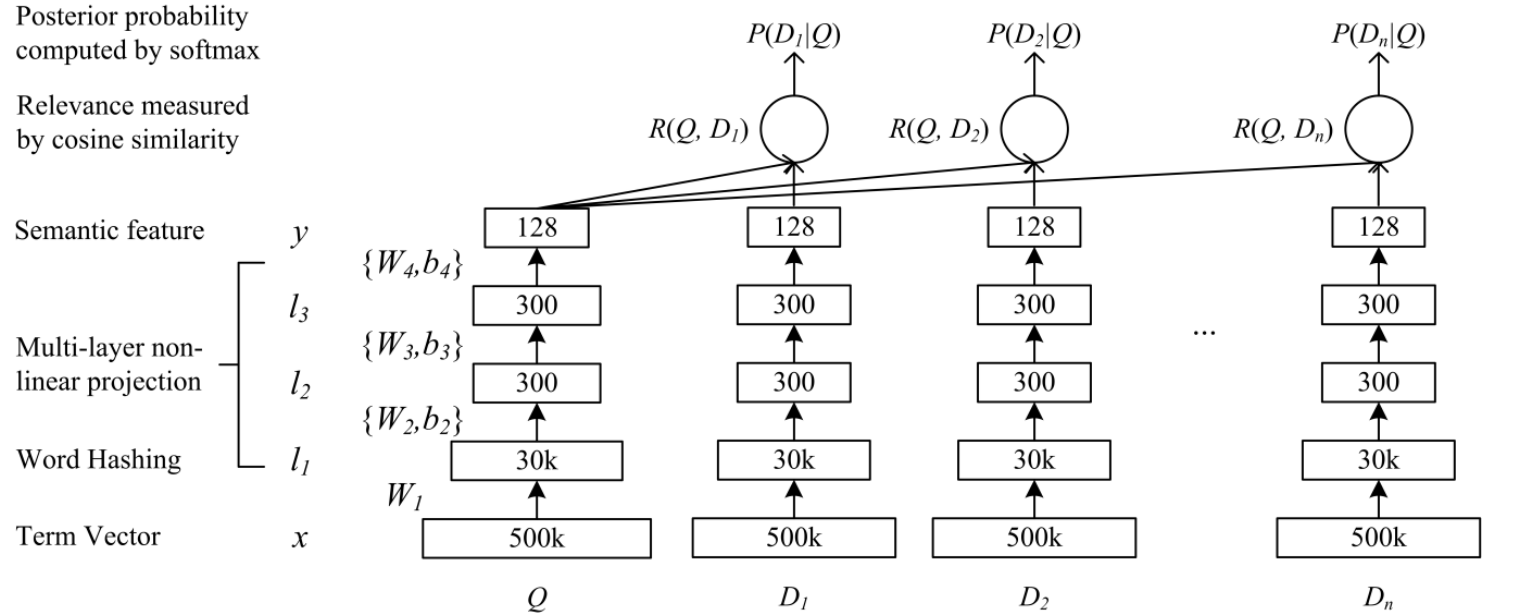
先来看其结构,我把DSSM分成了三个部分,embedding层对应图中的Term Vector,Word Hashing,特征提取层对应图中的,Multi-layer,Semantic feature,Cosine similarity,还有输出层Softmax,我们针对这三部分分别讲解。
embedding层
这里我把图中的Term Vector和Word Hashing都归在了embedding层,Term Vector是文本转向量后的值,论文中作者采用的是bag-of-words即词袋模型,我的代码中会采用one-hot的形式。然后是Word Hashing层,英文主流文本转vector的方式更多是采用embedding,但是该方法有一个致命的问题就是会出现OOV的问题,而作者提出了一种word hasing的方法,该方法一方面能降低输入数据的维度,其次也能保证不出现OOV的问题,接下来我们详细看下其原理。
word hashing
这里以good这个单词为例,分为三个步骤
- 在good两端添加临界符#good#
- 采用n-gram的方式分成多个部分,如果是trigrams那么结果是[#go, goo, ood, od#]
- 最终good将会用[#go, goo, ood, od#]的向量来表示
在英文中,因为只有26个字母,加上临界符是27个符号,3个字母的组合是有限的,即$A_{27}^3=17550$种可能,因此也就不会出现OOV的问题。
对于discriminative,discriminate,discrimination 三个单词的意思很像,他们的Word Hashing中也有大部分是相同的。这样两个不同的单词也有可能具有相同的tri-grams,针对这个问题论文中做了统计,这个冲突的概率非常的低,500K个word可以降到30k维,冲突的概率为0.0044%。
可见该方法对于英文来说是有效可行的,但是并不适合中文,在我的代码中,会采用字向量的形式,词典包含了大部分的中文,能有效降低oov的可能性。
特征提取层
接下来的结构就很简单了,三个全连接层,激活函数采用的是tanh,把维度降低到128,然后把两个序列的Semantic feature进行了余弦相似度计算,这里给一下前向传播的公式。
输出层
输出层也很简单,一个softmax,因为是计算相似度所以可以看成是二分类,细节不再赘述。
变体
随着深度学习的发展,CNN、LSTM被提出,这些特诊提取的结构也被应用到了DSSM中,其主要的区别就在于把特征提取层的全连接结构换成了CNN或者LSTM,在我的代码中只提供了普通版本的DSSM,而对于CNN或者说LSTM这些结构,在我的其他匹配模型中有用到,感兴趣的小伙伴也可以参阅我的其他匹配模型。



