ESIM详解
本文是我的匹配模型合集的其中一期,如果你想了解更多的匹配模型,欢迎参阅我的另一篇博文匹配模型合集
所有的模型均采用tensorflow进行了实现,欢迎start,代码地址
简介
ESIM模型主要是用来做文本推理的,给定一个前提premise $p$ 推导出假设hypothesis $h$,其损失函数的目标是判断$p$与$h$是否有关联,即是否可以由$p$推导出$h$,因此,该模型也可以做文本匹配,只是损失函数的目标是两个序列是否是同义句。接下来我们就从模型的结构开始讲解其原理。
结构
ESIM的论文中,作者提出了两种结构,如下图所示,左边是自然语言理解模型ESIM,右边是基于语法树结构的HIM,我的代码实现主要以ESIM为主,本文也主要讲解ESIM的结构,大家如果对HIM感兴趣的话可以阅读原论文。
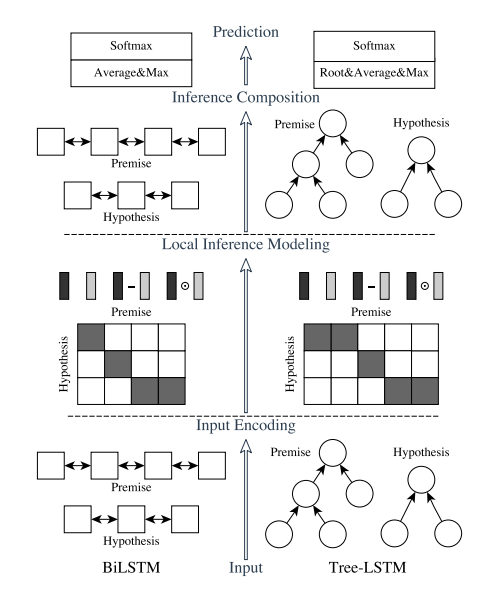
ESIM一共包含四部分,Input Encoding、Local Inference Modeling、 Inference Composition、Prediction,接下来会分别对这四部分进行讲解。
Input Encoding
我们先看一下这一层结构的输入内容,输入一般可以采用预训练好的词向量或者添加embedding层,在我的代码中采用的是embedding层。接下来就是一个双向的LSTM,起作用主要在于对输入值做encoding,也可以理解为在做特征提取,最后把其隐藏状态的值保留下来,分别记为$\bar{a_i}$与$\bar{b_j}$,其中i与j分别表示的是不同的时刻,a与b表示的是上文提到的p与h。
Local Inference Modeling
这一层的任务主要是把上一轮拿到的特征值做差异性计算。这里作者采用了attention机制,其中attention weight的计算方法如下:
然后根据attention weight计算出a与b的权重加权后的值,计算方法如下:
注意,这里计算$\tilde{a_i}$的时候,其计算方法是与$\bar{b_j}$做加权,而不是$\bar{a_i}$本身,$\tilde{b_j}$同理。
得到encoding值与加权encoding值之后,下一步是分别对这两个值做差异性计算,作者认为这样的操作有助于模型效果的提升,论文有有两种计算方法,分别是对位相减与对位相乘,最后把encoding两个状态的值与相减、相乘的值拼接起来。
Inference Composition
在这一层中,把之前的值再一次送到了BiLSTM中,这里的BiLSTM的作用和之前的并不一样,这里主要是用于捕获局部推理信息$m_a$和$m_b$及其上下文,以便进行推理组合。
最后把BiLSTM得到的值进行池化操作,分别是最大池化与平均池化,并把池化之后的值再一次的拼接起来。
Prediction
最后把$V$送入到全连接层,激活函数采用的是$tanh$,得到的结果送到softmax层。
小结
ESIM与BiMPM在相似度匹配任务中都是使用较多的模型,但是ESIM训练速度快,效果也并没有逊色太多,如果加入了语法树,其最终效果也能进一步的提升。